Apache Kafka,Purgatory以及多级时间轮
原文地址:Apache Kafka, Purgatory, and Hierarchical Timing Wheels

Apache Kafka有一个称为“请求Purgatory”的数据结构。 这个数据结构会hold住任何尚未达到标准的成功,但又尚未造成错误的请求。 问题是:我们如何有效地跟踪群集中数以万计的的满足要求的异步请求?
Kafka实现了几个不能立即回应的延时请求类型。 例子:
只有在所有同步副本已经确认写入之后,acks = all的产生请求才能被认为是完整的,并且如果领导失败,我们可以保证它不会丢失。
对于min.bytes = 1的提取请求只有在至少有1个byte的数据能够被消费者消费时才会被回答。 这允许“长时间轮询”,使得消费者不必忙于等待检查新数据到达。
这些请求被认为是完成的:
(a)他们所要求的标准完成
(b)或者发生一些超时
时刻增长这些异步操作的数量与连接的数量成比例,对于Kafka来说,这往往是成千上万的连接数量。
请求Purgatory被设计用于如此大规模的请求处理,但是旧的实现有一些缺陷。
在这个博客中,我想解释一下旧执行的问题以及新实现如何解决这个问题。 我也将呈现基准测试结果。
旧的Purgatory的设计
请求purgatory包括一个超时计时器和事件驱动处理的观察者列表哈希映射。 如果一个请求的条件得不到满足而不能马上满足,就需要把它放入Purgatory中。 当条件满足时,Purgatory中的请求会被完成,或者当超过请求的超时参数指定的时间时被强制完成(超时)。 在旧的设计中,它使用Java DelayQueue来实现定时器。
当请求完成时,请求不会立即从定时器或观察者列表中删除。 相反,完成的请求会在条件检查期间被删除。 当删除不跟上时,服务器可能会耗尽JVM堆并导致OutOfMemoryError。
为了缓解这种情况,一个单独的线程(称为收割者线程)在Purgatory中的请求数量(挂起或已完成)超过配置的数量时,清除Purgatory中完成的请求。 清除操作扫描定时器队列和所有观察者列表以找到完成的请求并删除它们。
通过将此配置参数设置为较低值,服务器可以表面上避免内存问题。 但是,如果服务器太频繁地扫描所有列表,则会付出比较大的性能损失。
新Purgatory的设计
新设计的目标是允许立即删除已完成的请求,并显着减少昂贵的清除过程的负担。 它需要交叉引用定时器和请求中的条目。 此外,强烈希望具有O(1)插入/删除成本,因为每个请求/完成都会发生插入/删除操作。
为了满足这些要求,我们设计了一个基于分级时间轮的新的Purgatory实现[1]。
分级时间轮
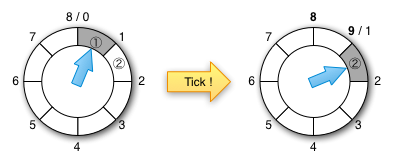
大小为n的定时轮具有n个时段,并且可以在n u个时间间隔内保持定时器任务。每个桶包含落在相应时间范围内的定时器任务。首先,第一个桶保存[0,u]的任务,第二个桶保存[u (n-1),u n)中的[u,2u),…,第n个桶的任务。每一个时间间隔单位u,计时器滴答并移动到下一个桶,然后终止所有计时器任务。所以,定时器从不在当前时间插入任务,因为它已经过期了。计时器立即运行过期的任务。因此,如果当前时间段为时间t,则在空闲时间之后,空的时间段将成为[t + u n,t +(n + 1)* u)的时间段。定时轮具有O(1)插入/删除(启动定时器/停止定时器)的开销,而基于优先级队列的定时器(例如java.util.concurrent.DelayQueue和java.util.Timer)具有O(log n)插入/删除成本。请注意,DelayQueue或Timer都不支持随机删除。
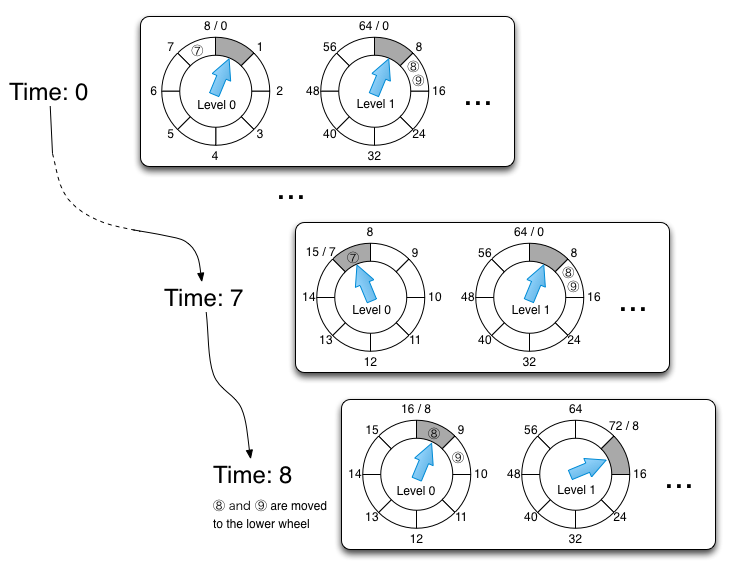
一个简单的时间轮的一个主要缺点是它假定一个定时器请求在距当前时间n u的时间间隔内。如果一个定时器请求超出这个时间间隔,这是一个溢出。分层的时间轮处理这种溢出。这是一个分层组织的时间轮代表溢出到上层轮子。最底层有最好的时间分辨率。时间分辨率越来越粗糙,如果某一级的轮子的分辨率为u,大小为n,则分辨率应该是第二级的n u,第三级的n2 * u,依此类推。在每个级别,溢出都被委托给高一级的车轮。当较高级别的轮子时间到达时,它将计时器任务重新插入较低级别。高一级的时间轮可以按需创建。当溢出存储桶中的存储桶到期时,其中的所有任务将被递归地重新插入定时器。然后任务被移动到更精细的轮子或被执行。插入(启动定时器)的开销是O(m),其中m是车轮的数量,通常与系统中的请求数量相比非常小,并且删除(停止计时)的开销仍然是O(1 )。
双向链轮列表中的时间轮桶
在新的设计中,我们使用自己的双向链表来实现时序轮中的桶。 双向链表的优点是它允许O(1)插入/删除一个列表项,如果我们有访问链表单元的话。
计时器任务实例在排队到计时器队列时将链接单元保存在自身中。 任务完成或取消时,使用保存在任务本身中的链接单元更新列表。
使用DelayQueue驱动时钟
一个简单的实现可以使用一个线程,唤醒每个单位时间,并做滴答,检查是否有任何任务在桶中。 Purgatory的单位时间是1ms(u = 1ms)。 如果最低级别的请求稀疏,这可能是浪费的。 通常情况下是这样的,因为大多数请求在插入最低级别的车轮之前是满足的。 如果一个线程只有在非空的存储桶过期才会唤醒,那将会很好。 新的Purgatory通过使用java.util.concurrent.DelayQueue类似于旧的实现,但是我们排队任务桶而不是单独的任务。 这种设计具有性能优势。 DelayQueue中的项目数量以桶的数量为上限,通常远小于任务数量,因此DelayQueue内的优先级队列的offer/poll操作的数量将显着减少。
清除watch列表
在旧的实现中,观察者列表的清除操作由总大小触发。问题是,即使没有太多请求清除,观察者列表也可能会超出阈值。发生这种情况时,会增加很多CPU负载。理想情况下,清除操作应该由观察者列出的已完成请求的数量触发。
在新设计中,已经完成的请求立即以O(1)成本从定时器队列中移除。这意味着任何时候定时器队列中的请求数量是待处理请求数量。因此,如果我们知道Purgatory中不同请求的总数,包括未决请求数量和已完成但仍然监视的数量的总和,我们可以避免不必要的清除操作。跟踪Purgatory中不同请求的确切数量是不太现实的,因为一个请求可能被监视,也可能不被监视,状态可能只在一瞬间变换。在新设计中,我们只粗略预估Purgatory中的请求总数,而不是试图维持正确的数量统计。
估计的请求数量按以下保持:
- 估计的请求总数E会随着新的请求被监视而增加。
- 在开始清除操作之前,我们将估计的总请求数重置为定时器队列的大小。这是当前的待处理请求的数量。如果在清除期间没有任何请求被添加到Purgatory,则E是清除后正确的请求数量。
- 如果清除过程中某些请求被添加到Purgatory,则E增加到E+新观察请求的数量。这可能被高估,因为有可能在清除操作期间完成一些新的请求并从观察者列表中删除。我们预计高估和高估的可能性很小。
基准测试
我们比较了两个Purgatory实施的入队表现,旧的实施和新的实施。这是一个微观基准。它只是衡量Purgatory入队的表现。Purgatory与系统的其他部分分离,并使用一个没有用处的测试要求。因此,真实系统中Purgatory的吞吐量可能会低于测试所显示的数量。
在测试中,请求的间隔假定遵循指数分布。每个请求都需要从对数正态分布中抽取一段时间。通过调整对数正态分布的形状,我们可以测试不同的超时率。
刻度大小为1ms,轮子大小为20.超时设置为200ms。请求的数据大小是100字节。对于较低的超时率情况,我们选择75%均线 = 60ms和50%均线 = 20。对于高超时率情况,我们选择75%均线 = 400ms和50%均线 = 200ms。总共有100万个请求在每次运行中排队。
请求由一个单独的线程主动完成。应该在超时之前完成的请求被排队到另一个DelayQueue。而一个单独的线程保持轮询并完成它们。实际完成时间无法保证准确性。
JVM堆大小设置为200M来重现内存紧张的情况。
结果表明,高排队率区域有显着差异。随着目标机率的提高,两种实施方式都能满足要求。然而,在低超时的情况下,旧的实现极限大约40000 RPS(请求每秒),而新的实现并没有显示任何显着的性能下降,在高超时的情况下,旧的实现极限大约25000 RPS,而新的实现在这个基准测试中达到了105000 RPS。
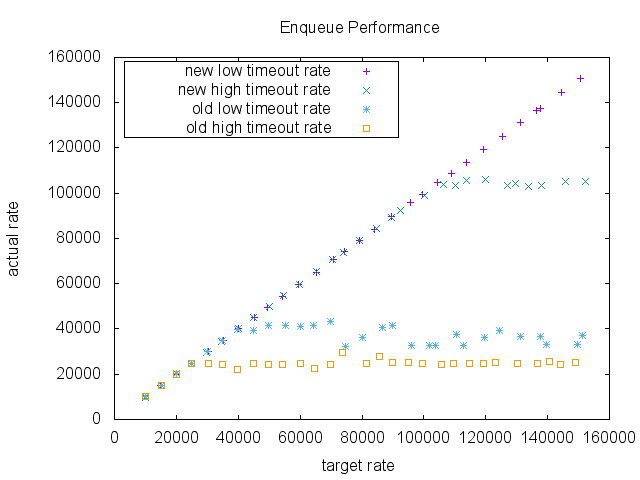
另外,在新的实现中CPU的使用情况要好得多。 请注意,由于可伸缩性的限制,旧的实现没有高于〜40000 RPS的数据点。 同时也注意到它的CPU时间在1.2左右饱和,而在新的实现中稳步上升。 这表明旧的实现可能由于同步而遇到并发问题。
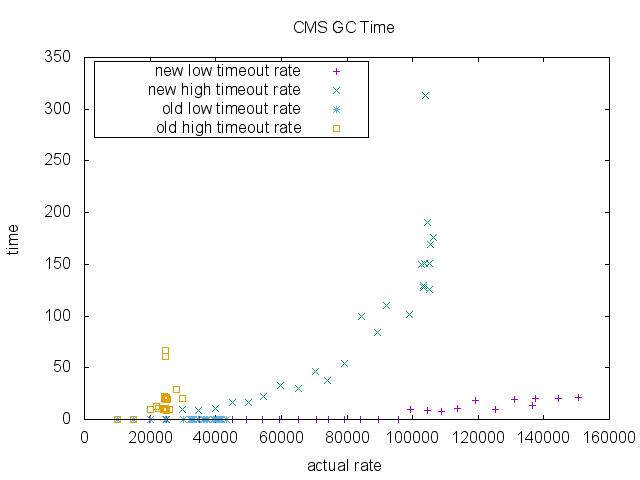
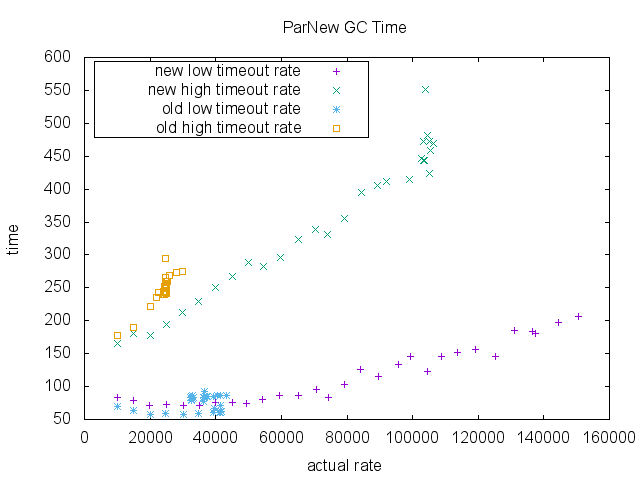
最后,我们测量了ParNew收集和CMS收集的总GC时间(毫秒)。 旧的设计和新的设计在维持的入队率没有太大差别。 再次注意,由于可伸缩性限制,旧的实现没有高于〜40000 RPS的数据点。
概要总结
在新设计中,我们使用多级时间轮作为定时器桶的超时定时器和DelayQueue按需提前时钟。 O(1)成本立即从计时器队列中删除已完成的请求。 桶仍然在延迟队列中,但桶的数量是有限的。 而且,在一个健康的系统中,大多数请求应该在超时之前完成,并且在离开延迟队列之前许多桶变空了。 因此,计时器应该很少有较低间隔的桶。 这种设计的优点是,定时器队列中的请求数量是任何时候的待处理请求数量。 这使我们能够估计需要清除的请求数量。 我们可以避免观察者列表的不必要的清除操作。 因此,我们在请求速率方面实现了更高的可扩展性,CPU使用率更高。